下载APP

【简答题】

The Real Death Of Print Vishwas Chavan travels a lot. As an informatician, he collects data on what types of animal live where in India to enter into a biodiversity database. Yet the specimens he hunts for have neither fur nor feathers, but yellowing pages and ageing dust-jackets. Much of the information Chavan seeks is in old, out of-print tomes that are scattered around the world; about 2,500 of the 7,000 books he has unearthed were written in the first half of the nineth century. To find them, Chavan has spent years trailing around libraries. He dreams of the day when books such as these are scanned and made available as digital files on the Internet. Chavan and other digitization visionaries paint a future in which books no longer gather dust on shelves, but exist as interconnected nodes in a vast web of stored literature, all accessible at the click of a mouse. So instead of hunting for specific books, scholars could search for specific information, customizing searches to suit their needs. A few years ago, Chavan’’s dream seemed little more than a castle in the air. True, a number of mostly volunteer-driven or publicly funded projects had been scanning books and them freely available on the Internet. But most efforts were limited. In December 2004, the Internet searchengine company Google announced plans to change that. It said it would scan millions of books from five major libraries: the university libraries of Oxford, Harvard, Stanford and Michigan, and the New York Public Library. The announcement energized other organizations in the United States and in Europe, which soon declared similar plans to scan and catalogue millions of books. The move to digitize books is set to transform the worlds of publishers, librarians, authors, readers and researchers. Obscure specialist titles could find new readerships; librarians and information specialists will have to develop tools to catalogue and navigate this labyrinth (迷宫) of data; and authors and publishers may soon have to start thinking in digital dimensions, just as website designers and writers already do. Bloody revolution But revolutions are rarely bloodless and this one could soon get ugly. In the United States authors and publishers are squaring up against Google for a legal fight over copyright. Opinion is divided over whether the scanning projects being implemented by companies such as Google and Amazon will hand control of the world’’s literature to private enterprise — and, if so, what this could mean. And with several independent scanning projects under way, it is still not clear how much of the information will be freely available, or where and how it can all be coordinated and accessed. The idea to digitize books and make them available online has been around since the beginning of Internet in the early 1970s. When the US Declaration of Independence was typed in and sent to everyone on a computer network on the night of 4 July 1971, it marked the birth of Project Gutenberg, the first book-digitization venture. Since then, the project’’s 20,000 volunteers have scanned or typed in about 50,000 out-of copyright books, says its founder Michael Hart, who works in the basement of his home in a, Illinois, and, like the project’’s volunteers, for free. Projects such as this are driven by the idealistic desire to make knowledge and literature freely accessible to all, but also by the benefits of having book collections easily searchable. "Being able to find it online is pretty much the same as having it online," says David Weinberger of the Berkman Center for Internet and Society. Assets such as searchability have prompted the National Science Foundation (NSF) in Arlington, Virginia, to get involved in an open-access enterprise called the Million Book Project. This is an international scanning effort with many participants, including Carnegie Mellon University. Since the project began in 2002, about 600,000 out-of-copyright books have been scanned, although only about half of them are currently available online. The scanning takes place in India and China, with books being shipped there temporarily from libraries around the world. Made to fit Searchability is also the main driving force behind commercial plans to scan books, including texts whose copyright has yet to expire. For example, if their products have been digitized, online booksellers can allow customers to search within books and browse a few pages before deciding to buy. In the United States, with the publisher’’s permission, Amazon puts searchable digital data from mostly copyrighted books online. Amazon says that several hundred thousand books are currently available for searching. Amazon also offers the option of purchasing e-books and e-documents on its website, which can be viewed after downloading them to a portable reading device. The company expects these services to drive additional sales. Its ’’search inside the book’’ feature increases sales by 8%, the company says. Scientific publishers, such as the US National Academies Press also see increased print sales when they allow their books to be viewed online. But Google doesn’’t mention money in its announcement that it plans to make the contents of millions of copyrighted books searchable as part of its Google Book Search project. Its spokesman, Nate Tyler, says Google’’s motivation is to include literature that is currently only available offline in its mission to make information universally accessible. But the possibility that the company could gain financially from the move has raised hackles among US authors and publishing organizations. In the autumn of this year, the Authors Guild and the Association of American Publishers filed a lawsuit against Google for copyright infringement. They complained that Google hadn’’t asked them for permission to scan copyrighted books. Google has obtained the go-ahead from publishers to include some copyrighted works as part of its Book Search project, but not all. It argues that it does not need to seek permission for every book, because what it plans to do is permissible according to the "fair use" exception of US copyright law. This allows copying for uses such as teaching, scholarship or research. Google will, for example, not make the full text available, but only show "snippets" of text around the search results if a book is still copyrighted. The company says that people are more likely to buy or borrow a book if they can search it this way, adding that the snippets are similar to the card catalogues found in libraries. But Paul Aiken of the Authors Guild in New York City argues that the act of scanning the works is copyright infringement (侵害) no matter how the texts are used. The outcome of the lawsuit will depend on the courts’’ decisions over how the concept of fair use applies in the age of digital books and the Internet. Meanwhile, the rest of the scanning world is watching from the sidelines, and being careful to scan only books that are out of copyright, or to obtain the publisher’’s permission before scanning anything. Google’’s plan has shaken up the digital-book world in other ways too. For one thing, many believe that its size and resources mean Google can pull of this feat — so large-scale repositories of digital books seem a more realistic and immediate prospect than ever before. Google has also galvanized its competitors, both public and private to redouble their efforts, and has placed a question mark over the future of libraries and librarians. "I think Google is in a class by itself because of the quantity of money and the level of centralization," says Daniel Greenstein, librarian of the California Digital Library in Oakland, California. "Google has paved the way, created the appetite for this kind of activity, and anxiety on the part of libraries and publishers." Out with the old But Michael Gorman, president of the American Library Association, says he is not worried that libraries could become obsolete. As well as providing access to books, they serve as a place for people to meet and study, he says. And librarians’’ expertise in information management will still be needed. "We are not worried about our own jobs," agrees Dennis Dillon, associate director of the research services division of the University of Texas libraries at Austin. "The job is changing, which makes it even more fulfilling than it was before." But Gorman is worried that over-reliance on digital texts could change the way people read — and not for the better. He calls it the "atomization of knowledge". Google searches retrieve snippets and Gorman worries that people who confine their reading to these short paragraphs could miss out on the deeper understanding that can be conveyed by longer, narrative prose. Dillon agrees that people use e-books in the same way that they use web pages: dipping in and out of the content. The founder of Project Gutenberg works for the projects__________.
题目标签:迷宫
举报


参考答案:

参考解析:


刷刷题刷刷变学霸
举一反三
【单选题】下图是一个迷宫,S0是入口,Sg是出口,把入口作为初始节点,出口作为目标节点,通道作为分支,画出从入口S0出发,寻找出口Sg的状态树。根据深度优先搜索方法搜索的路径是________ 。
A.
s0-s4-s5-s6-s9-sg
B.
s0-s4-s1-s2-s3-s6-s9-sg
C.
s0-s4-s1-s2-s3-s5-s6-s8-s9-sg
D.
s0-s4-s7-s5-s6-s9-sg
【多选题】对放射治疗的加速器,安全联锁装置只有在()参数选定后,控制台必须显示上述辐照参数预选值,并与治疗室的一致,治疗室迷宫的防护门关闭的条件满足时,才允许进行照射。
A.
射线类型
B.
射线能量
C.
吸收剂量预选值
D.
照射方式
E.
过滤器规格
【单选题】“在迷宫中搜寻比停留在没有奶酪的地方更安全”是唧唧在什么时候写的?()
A.
在奶酪C站时
B.
在到奶酪C站前
C.
在离开C站后,独自寻找奶酪时
D.
在离开C站后,同哼哼一起寻找奶酪时
【单选题】患者男,61岁,因“心悸、气短伴晕厥10年,加重3个月”来诊。查体:BP190/85mmHg,HR105次/min。ECG:心房颤动、左前束支传导阻滞、V2~V5导联ST-T改变。诊断为风湿性心脏病、联合瓣膜病(重度左房室瓣狭窄伴轻度关闭不全+重度主动脉瓣狭窄)、心功能Ⅳ级。拟于体外循环下行左房室瓣、主动脉瓣置换术、迷宫射频消融术。体外循环转流过程中,患者MAP105mmHg,SvO255%,灌注...
A.
不用处理
B.
提高灌注泵速
C.
提高氧流量
D.
应用扩血管药物并加深麻醉
E.
应用扩血管药、加深麻醉并提高灌注泵速
【单选题】你想利用大鼠学习走迷宫的实验范式来研究观察者偏见对实验结果的影响。以下实验流程不正确的是
A.
给主试一个秒表和一个迷宫装置,告诉主试记录大鼠从放入迷宫到走出迷宫的时间作为实验数据。
B.
招募十名不懂心理学的大学生作为主试,每人分配两组大鼠,并且告知他们拿到的大鼠哪个是高能力组、哪个是低能力组。
C.
实验结果发现高能力大鼠走出迷宫的时间均值比低能力大鼠30秒,于是你得到结论观察者偏见对实验结果有影响。
D.
随机选择二十组每组 10只没有走过迷宫的同龄大鼠,每组雌雄各半,随机标记为十个高能力组和十个低能力组。
【单选题】依次填入下列各句中横线处的词语,最恰当的一项:①美国政府奉行紧缩性财政政策,借助外国资金开展基础设施建设,中国对此。②这个森林像个迷宫,还好我们的原住民向导对它,我们才不致迷失方向。③展览会的说明书写得简明扼要,使人对展览内容。④大唐名相狄仁杰在破案过程中,使得一个个悬案水落石出,堪称一代神探。
A.
一目了然 洞若观火 明察秋毫 了如指掌
B.
了如指掌 明察秋毫 洞若观火 一目了然
C.
明察秋毫 一目了然 了如指掌 洞若观火
D.
洞若观火 了如指掌 一目了然 明察秋毫
【单选题】患者男,61岁,因“心悸、气短伴晕厥10年,加重3个月”来诊。查体:BP 190/85 mmHg,HR 105次/min。ECG:心房颤动、左前束支传导阻滞、V ~V 导联ST-T改变。诊断为风湿性心脏病、联合瓣膜病(重度左房室瓣狭窄伴轻度关闭不全+重度主动脉瓣狭窄)、心功能Ⅳ级。拟于体外循环下行左房室瓣、主动脉瓣置换术、迷宫射频消融术。闭合胸骨时,患者突然心率增快、律齐、窄QRS波群,伴明显血压...
A.
静脉注射盐酸胺碘酮
B.
静脉注射艾司洛尔
C.
静脉注射地尔硫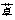
D.
立即电复律
E.
加快肾上腺素泵注速度
【单选题】下列关于光电感烟火灾探测器迷宫式光栅作用的表述中,正确的是()
A.
便于烟雾进入光敏室
B.
阻止外界光线射入光敏室
C.
增加烟雾在探测器内的停留时间
D.
减少烟雾在探测器内的停留时间